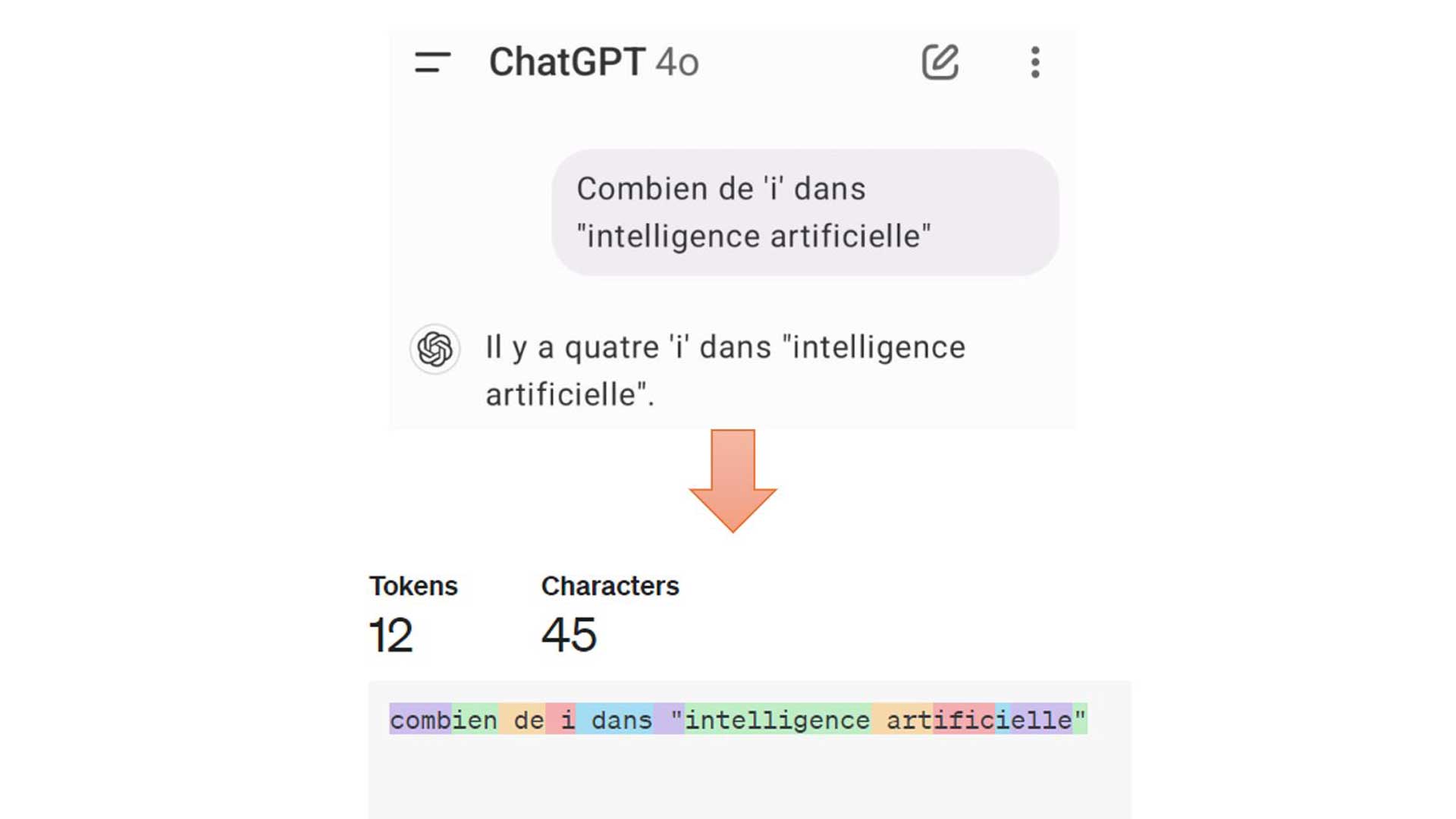
Il y a environ un mois, j’avais fait un post sur ce sujet.
J’avais posé une question simple (pour nous, humains) aux IA GPT-4 et Claude-3.5-Sonnet : combien de « i » dans « intelligence artificielle » ?
Résultat, elles se trompent presque à chaque fois.
Cela a suscité de grandes discussions car beaucoup pensent que le problème vient du prompt (la manière de poser la question) :
« Chez moi, ça marche, c’est une question de prompt… »
« Avec Copilot, ça fonctionne… »
« J’ai amélioré le prompt et ça donne la bonne réponse… »
etc.
En réalité, tous les LLM (modèles de langage comme ChatGPT, Claude, Llama) font la même « erreur ».
Les IA génératives ne perçoivent pas les mots comme une suite de caractères individuels, mais comme des tokens (un mot, une partie de mot ou même un caractère).
Cela leur permet de gérer efficacement le texte en tenant compte du contexte global plutôt que du détail exact de chaque caractère.
Dans l’image du post, on voit le découpage de la phrase en tokens colorisés par GPT-4.
Pour simplifier, c’est ainsi que le LLM se représente la phrase avant de la traiter.
Bien que les LLM puissent comprendre et traiter des concepts liés aux mots et aux lettres, ils ne savent pas compter intrinsèquement le nombre de lettres dans un mot.
Ce n’est pas leur manière de traiter l’information.
Ce sont des modèles probabilistes, dont le job consiste à vous donner une réponse statistiquement probable.
Parfois, ils donneront la « bonne » réponse, parfois non.
Il est important de bien comprendre la nature de ces nouveaux outils pour les appréhender correctement.
Si vous pensez toujours que le problème est lié au prompt, un conseil : formez-vous, vite !